Breaking the Real-Time Generation Bottleneck: Soul Zhang Lu Team Releases Open-Source Model SoulX-LiveAct
Targeting Long-Duration Stability and Real-Time Inference, the Soul Zhang Lu Team Open-Sources the SoulX-LiveAct Model
Recently, the Soul Zhang Lu team announced that its AI research division, Soul AI Lab, has officially released the open-source model SoulX-LiveAct. As a significant technical achievement in real-time digital human generation, the model is built around two core objectives—“long-duration stability” and “real-time streaming”—and systematically optimizes existing generation paradigms. Against the backdrop of rapidly expanding digital human live streaming, video podcasts, and real-time interactive scenarios, SoulX-LiveAct charts a new path for bringing real-time generation technology into production-grade deployment.

As artificial intelligence accelerates its footprint in content generation, digital human technology has gradually shifted from experimental demonstrations to real-world applications. However, during prolonged operation, traditional generation models often fail to maintain consistent performance. When video generation extends to minutes or even hours, models tend to suffer from identity drift, detail degradation, and frame flickering, while inference costs rise in tandem with duration.
To address these challenges, SoulX-LiveAct adopts the autoregressive diffusion (AR Diffusion) paradigm as its overarching architecture and introduces two key mechanisms—Neighbor Forcing and ConvKV Memory—to build a stability framework designed for long-sequence generation. In practice, the model uses chunks as its basic generation unit, producing video segment by segment with contextual continuity between chunks. Within each chunk, the diffusion model handles fine-grained detail modeling, while condition information is passed between chunks to maintain consistent motion and identity, forming a complete streaming inference loop.
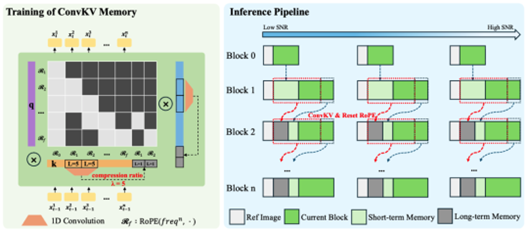
Regarding the core mechanisms, Neighbor Forcing propagates latent information from adjacent frames within the same diffusion step, enabling the model to make predictions in a unified noise semantic space. This effectively reduces instability caused by distributional inconsistencies between training and inference. Meanwhile, ConvKV Memory structurally compresses historical information, transforming the traditionally linearly growing cache into a “short-term precise + long-term compressed” format: recent information retains high precision for local detail, while older information is compressed through lightweight convolution—controlling memory usage while preserving critical contextual information. Additionally, the model uses RoPE Reset to align position encodings, further mitigating positional drift during long-sequence generation.
In terms of inference efficiency, SoulX-LiveAct emphasizes “stable latency” and “constant GPU memory.” Through the ConvKV Memory mechanism, historical information no longer grows linearly over time, keeping memory usage within a fixed range. This design ensures that computational and communication costs remain stable during prolonged operation, without significant increases as video length extends. In actual performance, the system achieves 20 FPS streaming inference at 512×512 resolution on 2×H100/H200 hardware, with end-to-end latency of approximately 0.94 seconds and a computational cost of 27.2 TFLOPs/frame, demonstrating a well-balanced trade-off between real-time capability and resource efficiency.
Across multiple evaluation benchmarks, SoulX-LiveAct also showcases its comprehensive performance advantages. On the HDTF dataset, the model achieves a Sync-C of 9.40 and Sync-D of 6.76, with distribution similarity scores of 10.05 FID and 69.43 FVD. In VBench, it scores 97.6 for Temporal Quality and 63.0 for Image Quality, with VBench-2.0 Human Fidelity reaching 99.9. On the EMTD dataset, the model maintains leading performance with 8.61 Sync-C and 7.29 Sync-D, achieving 97.3 Temporal Quality and 65.7 Image Quality in VBench, with Human Fidelity at 98.9. These results demonstrate the model’s strong capabilities in lip-sync accuracy, motion consistency, and overall visual stability.

Based on this performance profile, SoulX-LiveAct is capable of supporting a wide range of application scenarios requiring sustained online operation, including digital human live streaming, AI-powered education, smart service kiosks, and knowledge content production. In open-world interactive settings, digital characters must maintain consistent expressiveness throughout extended interactions. SoulX-LiveAct’s performance on full-body motion datasets and its real-time streaming inference capabilities provide the foundational support for such complex use cases.
The release of SoulX-LiveAct also extends the Soul AI team’s technical roadmap in real-time digital humans. Previously, the team had open-sourced SoulX-FlashTalk and SoulX-FlashHead, exploring ultra-low latency and lightweight deployment respectively. Additionally, the team has released models and modules in speech and interaction, including SoulX-Podcast, SoulX-Singer, and SoulX-Duplug, progressively building a multimodal technology ecosystem centered on “real-time interaction.”
Through the continued open release of models and technical solutions, the Soul Zhang Lu team is not only driving the iteration of its own AI capabilities but also providing the developer community with reusable technical foundations, fostering the exploration and deployment of more application scenarios.




